Hi All, I am just wondering what does it meant by ‘gwas_credible_sets’ under datasourceId ? Is it the L2G ML model score or specifically coloc evidence ?
I suspect you refer to the value in associationsByDatasourceDirect or associationsByDatasourceIndirect datasets. In both cases, this value is the association score resulting from aggregating all evidence for the same Target-Disease pair. In the platform website, it corresponds to the blue cells in the associations page. More details here
If you are looking after L2G evidence score, you will need to look at the evidence dataset, which will have one single row per credible set-gene pair. You will want to restrict to gwas_credible_sets as sourceId and use the score column to find any L2G prediction above 0.05.
Thanks for the swift reply David @ochoa. I am looking at association_by_datasource_direct and I am particularly interested in datatypeID==genetic_asscoation . I am just wondering if it is a aggregated score of all evidences, why does it still lists gene2phenotype, gene_burden, genomics_england, eva, clingen, orphanet, uniprot_literature, uniprot_variants in addition to gwas_credible_sets ? Did gwas_credible_sets replaced ot_genetics_portal score from previous versions ?
The association_by_datasource_direct would contain:
association - refers to target-disease aggregated scores derived from evidence
by_datasource - specifies the evidence is aggregated at the datasource-level (e.g. gene_burden, gene2phenotype, etc.)
direct - implies there is no aggregation of evidence using the ontology structure. Every evidence needs to be for the exact same target and disease and not descendants in the ontology.
You can find 6 different association datasets with different combinations of the above in the Downloads page. If instead you are looking for the aggregation of evidence in all genetic data sources you are probably more interested in the association_by_datatype_direct which would aggregate all genetic evidence from all sources (e.g. gene2phenotype, genomics_england, etc.) into a single score by target-disease pair. As a result, the schema of this dataset will not have datasourceId on it:
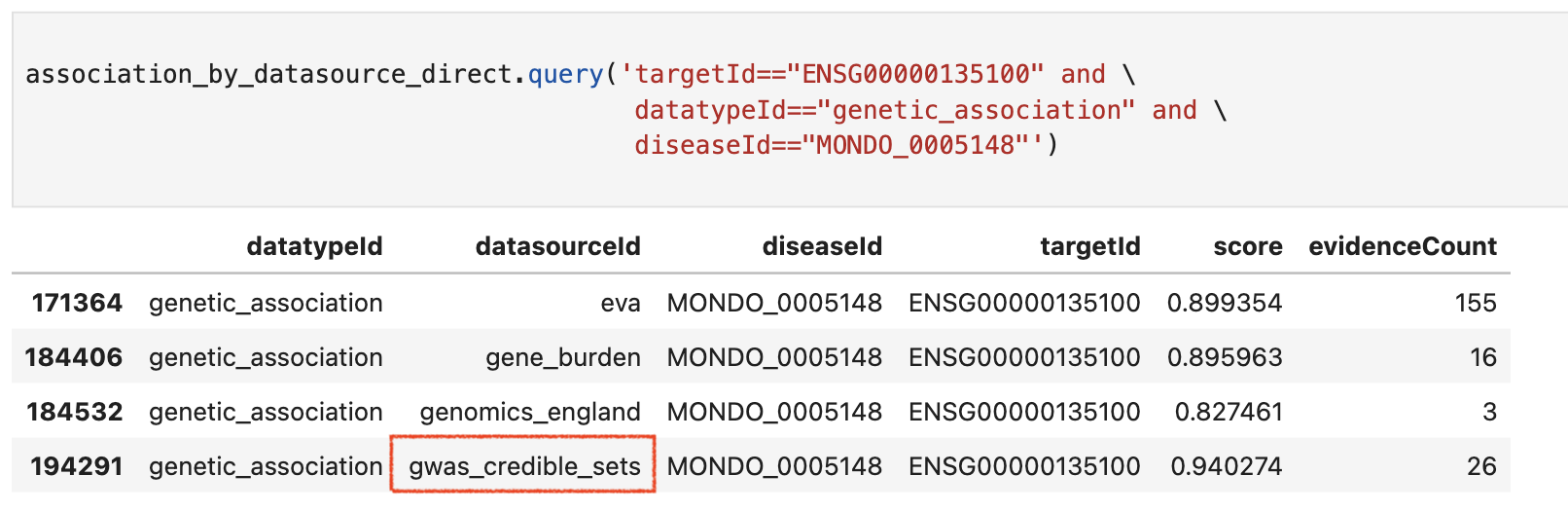
Thansk David. Super useful. What does gwas_credible_sets refer to in association_by_datasource_direct ? Is it coloc evidence or L2G model score ? Attaching an example
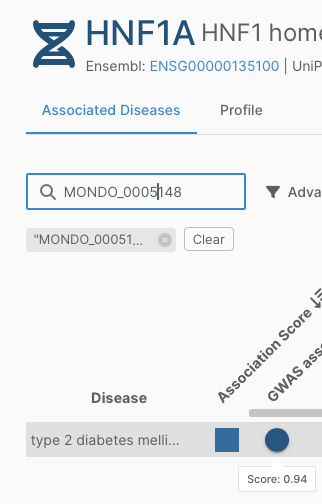
This is the result of aggregating all the L2Gs for all gwas credible sets pointing to that gene (content of the table when clicking on the blue dot). That data is available is the evidence dataset as described in my first comment